第一步:基础检查(90% 的问题出在这里)
在开始复杂的排查之前,请务必先确认以下几点,因为它们是最常见的原因。
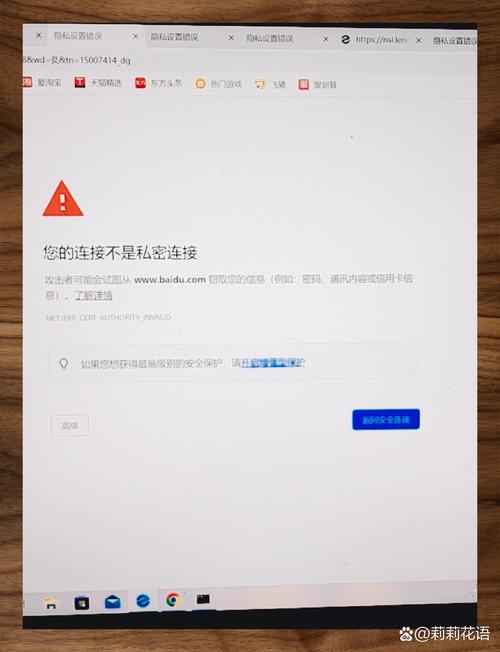
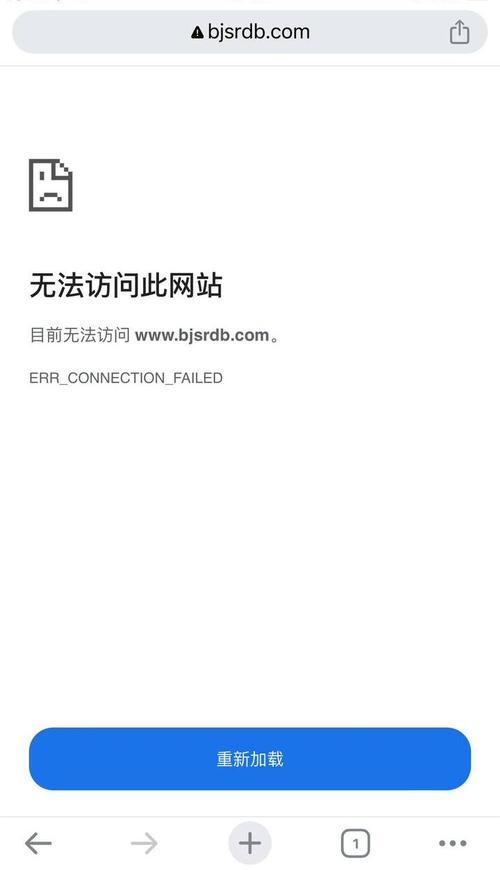
网站是否可以正常访问?
这是最基本的一步,在浏览器中打开你的网站主页,确保:
- 页面能加载出来,没有显示“404 Not Found”、“500 Internal Server Error”等错误。
- 完整,图片、文字、样式等都能正常显示。
- 网站没有被防火墙或安全软件屏蔽,尝试在不同的网络环境下(比如手机流量、朋友家的网络)访问,看是否正常。
如果网站本身都无法访问,Google 抓取器自然也无法访问。
robots.txt 文件是否禁止了抓取?
robots.txt 是一个位于网站根目录的纯文本文件,它告诉搜索引擎哪些页面可以抓取,哪些不可以,这是最常见的原因之一。
如何检查:
在浏览器地址栏中输入:你的域名.com/robots.txt
https://www.example.com/robots.txt
寻找以下问题:**
- User-agent: Googlebot 后面跟着
Disallow: /:这表示完全禁止 Googlebot 抓取你网站的所有页面,除非你有特殊原因,否则这行代码应该被删除或注释掉(用 注释)。 - 关键的路径被
Disallow:检查是否Disallow了你的主页、分类页或文章列表页。Disallow /admin/(禁止抓取管理后台,正确)Disallow /category/(错误!禁止抓取所有分类页,这会导致 Google 无法发现你的内容)Disallow /(错误!禁止抓取整个网站)
如何修复:
- 确保你的
robots.txt文件没有意外地阻止了 Googlebot。 - 如果不确定,可以暂时将
robots.txt文件删除或重命名(例如改为robots.txt.bak),然后观察 Google Search Console 是否能抓取。注意:这只是排查手段,问题解决后应恢复正确的robots.txt文件。
网站是否设置了 noindex
noindex 是一个 HTML 标签(通常放在 <head> 部分),它告诉搜索引擎“请索引这个页面,但不要在搜索结果中显示它”,如果所有页面都设置了 noindex,Google 虽然可能抓取,但不会收录。
如何检查:
- 使用 Chrome 浏览器开发者工具:
- 打开你的网站主页。
- 按
F12键打开开发者工具,切换到 "Elements" (元素) 标签页。 - 按
Ctrl+F(或Cmd+F) 搜索noindex。 - 查看是否有类似
<meta name="robots" content="noindex, follow">的标签。
- 使用 SEO 检查工具:如 Screaming Frog SEO Spider 等工具可以批量扫描你网站的所有页面,快速找出设置了
noindex的页面。
如何修复:
删除或修改所有页面中不必要的 noindex 标签,除了“感谢留言”、“注册成功”等特定页面外,你的主要内容页(文章、产品页等)都不应该设置 noindex。
第二步:技术性检查(使用 Google Search Console)
Google Search Console (GSC) 是诊断此问题的官方首选工具,如果你还没有添加你的网站,请立即添加。
检查“覆盖范围”报告
在 GSC 的左侧菜单中,找到“覆盖范围”(Coverage)报告。
- 有效的:这部分页面 Google 已经成功抓取并索引,是好的。
- 错误:这部分页面 Google 在抓取时遇到了问题。这是你最需要关注的地方!
- 已排除:这部分页面 Google 知道存在,但由于
robots.txt或noindex等原因被排除了索引,如果这里有你不希望被排除的页面,说明第一步的检查有遗漏。
点击“错误”标签,查看具体的错误类型:
- 服务器错误 (5xx):你的服务器出了问题,联系你的主机商。
- 未找到 (404):页面不存在了,检查链接是否错误,或者页面是否被误删。
- 被 robots.txt 阻止:确认
robots.txt文件配置是否正确(参考第一步)。 - 抓取被延迟:通常由服务器响应慢引起,继续看下一步。
- 其他问题:如“提交的网址过大”、“重定向过多”等,GSC 会给出具体原因。
检查“抓取工具”下的“抓取统计”
这个报告展示了 Googlebot 尝试抓取你网站的频率和成功率。
- 下载字节数:如果这个数字长时间为 0 或非常低,说明 Googlebot 几乎没有访问你的网站。
- 页面总数:如果这个数字很低,说明 Googlebot 发现的页面很少。
运行“URL 检查”工具
这是 GSC 最强大的功能之一。
- 在 GSC 的顶部,输入你想检查的具体网址(通常是你的主页)。
- 点击“运行”。
- 工具会告诉你 Google 是否索引了这个页面,并模拟 Googlebot 的抓取过程。
- 如果抓取失败,它会明确指出失败的原因,
- “无法抓取此网址”
- “在 robots.txt 中被阻止”
- “服务器返回了错误”
- “页面加载时出错”(可能是 JavaScript 渲染问题)
第三步:服务器和连接问题检查
GSC 显示“服务器错误”或“抓取被延迟”,问题可能出在你的服务器上。
服务器响应速度和稳定性
- 使用工具测试:访问 GTmetrix 或 WebPageTest,输入你的网址,它们会详细分析你的页面加载速度,并指出服务器响应时间是否过长。
- Google PageSpeed Insights:同样可以检查性能问题。
- 服务器宕机:如果你的服务器经常宕机或响应超时,Googlebot 会放弃抓取,检查你的主机控制面板,看是否有服务器负载过高、内存不足等问题,联系你的主机商寻求帮助。
防火墙或安全插件
- 服务器级防火墙:如 Cloudflare、Sucuri 等,它们的设置过于严格可能会阻止 Googlebot 的 IP 地址。
- 检查 Cloudflare:进入 "Firewall" -> "Tools" -> "IP Access Rules",确保没有阻止 Googlebot 的 IP 段(如
249.64.0/19),你也可以暂时将安全级别调为“Off”进行测试。
- 检查 Cloudflare:进入 "Firewall" -> "Tools" -> "IP Access Rules",确保没有阻止 Googlebot 的 IP 段(如
- 网站安全插件:如果你使用的是 WordPress 等 CMS,安装的安全插件(如 Wordfence, iThemes Security)可能会将 Googlebot 误判为恶意爬虫而拦截,检查插件的设置,将 Googlebot 加入白名单。
DNS 和主机记录
确保你的域名解析(DNS)设置正确,并且指向了正确的主机服务器,错误的 DNS 设置会导致 Google 无法找到你的服务器。
第四步:高级问题排查
如果以上所有步骤都正常,但 Google 仍然无法抓取,可能是一些更深层的问题。
JavaScript 渲染问题
Google 的抓取工具现在可以执行 JavaScript,但这并不意味着它做得和浏览器一样好,如果你的网站严重依赖 JavaScript 来加载主要内容(特别是 SPA 单页应用),Googlebot 可能无法正确抓取。
- 如何测试:在 GSC 的“URL 检查”工具中,点击“在手机上抓取”或“在桌面上抓取”,抓取完成后,查看“已抓取并呈现”的选项卡,这里会显示 Googlebot 看到的最终 HTML 代码,检查里面的内容是否和你浏览器中看到的一致,如果内容缺失,JS 渲染问题。
- 如何修复:
- 实现服务器端渲染或静态站点生成。
- 使用
prerender.io等服务。 - 确保关键内容在初始 HTML 中就存在,而不是通过异步加载。
反向代理问题
如果你的网站架构中使用了反向代理(如 Nginx、Varnish),配置错误也可能导致 Googlebot 无法访问。
- 如何检查:查看服务器的访问日志,尝试用
curl命令模拟 Googlebot 访问你的网站:curl -A "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" -v 你的域名.com
观察返回的 HTTP 状态码和响应头,看是否有异常。
网站结构问题
- 没有内部链接:Googlebot 通过外部链接(如其他网站链接)第一次访问你的网站,但它进入后发现没有任何内部链接可以点击,它就很难发现其他页面,确保你的主页、导航栏、侧边栏等有清晰的内部链接结构。
- 页面太深页面埋藏在很深的目录下(如
a/b/c/d/page.html),Googlebot 可能不会去抓取。
总结与行动计划
-
立即行动:
- 检查网站是否可访问。
- 检查
robots.txt文件,确保没有禁止 Googlebot。 - 检查
noindex,确保主要内容页没有被禁止索引。 - 将网站添加到 Google Search Console,这是诊断的核心。
-
深入诊断:
- 在 GSC 的“覆盖范围”报告中,查看所有“错误”,并根据提示修复。
- 使用 GSC 的“URL 检查”工具,对主页和几个重要页面进行抓取测试,看具体失败原因。
-
技术排查:
- 如果是服务器问题,检查服务器响应速度、防火墙设置,联系主机商。
- 如果怀疑是 JavaScript 问题,使用 GSC 的“在手机上抓取”功能,对比渲染结果。
-
最后手段:
- 如果所有方法都无效,尝试在 Google Search Console 中“重新提交sitemap.xml”,并手动提交几个关键页面的 URL,以“请求索引”的方式,看看 Google 是否能处理。
按照这个流程,你基本上可以定位并解决 99% 的“Google 无法抓取网站”的问题,祝你排查顺利!


