下面我将从项目背景、核心功能、技术架构、关键挑战和未来趋势等多个维度,为您全面解析一个“Java互联网监管项目”。
(图片来源网络,侵删)
项目背景与目标
互联网监管项目通常由政府机构、大型企业或行业协会主导,旨在建立一个集中化、智能化的平台,对互联网信息、内容、交易、用户行为等进行合规性审查、风险预警和违规处置。
核心目标:
- 合规性保障: 确保平台上的内容、交易和服务符合国家法律法规(如《网络安全法》、《数据安全法》、《个人信息保护法》等)和行业规范。
- 风险防范: 主动识别和处置网络谣言、色情低俗、暴力恐怖、赌博诈骗、违法广告等有害信息,防范金融风险、社会稳定风险。
- 内容治理: 维护健康、清朗的网络空间,提升用户体验和平台公信力。
- 数据驱动决策: 通过对海量数据的分析,为政策制定、市场监管提供数据支持和决策依据。
核心功能模块
一个完整的Java互联网监管项目通常包含以下几个核心模块:
数据采集与接入层
这是整个系统的基础,负责从各种来源获取数据。
(图片来源网络,侵删)
- 网站/APP爬虫: 使用Java爬虫框架(如WebMagic, Jsoup, HttpClient)定时抓取目标网站、APP的公开内容。
- API对接: 与各大社交媒体平台、电商平台、内容平台通过开放API或私有接口对接,获取结构化数据(如用户信息、商品信息、评论、交易记录)。
- 日志采集: 使用ELK (Elasticsearch, Logstash, Kibana) 或 Flume 等技术,实时采集服务器访问日志、用户行为日志、业务系统日志。
- 数据源管理: 对接外部数据源,如黑名单库、知识图谱、权威信息发布平台等。
数据处理与存储层
负责对采集到的数据进行清洗、转换、加工和持久化存储。
- 数据清洗: 使用Java的Spark Streaming、Flink或传统批处理框架(如Spring Batch)对数据进行去重、格式化、标准化处理。
- 数据存储:
- 关系型数据库: 存储结构化数据,如用户信息、审核任务、处置记录等,常用 MySQL 或 PostgreSQL。
- NoSQL数据库:
- Elasticsearch: 核心存储和搜索引擎,用于存储海量文本内容(如帖子、评论),并提供强大的全文检索、聚合分析能力。
- HBase / MongoDB: 存储非结构化或半结构化数据,如原始爬取数据、图片、视频的元信息。
- 大数据存储: 对于海量历史数据,使用 HDFS (Hadoop Distributed File System) 进行存储。
核心业务逻辑层
这是监管系统的“大脑”,负责实现核心的监管规则和逻辑。
-
内容审核引擎:
- 规则引擎: 使用Drools等规则引擎,配置大量基于关键词、正则表达式、业务逻辑的审核规则,进行初筛。
- AI模型服务: 集成NLP(自然语言处理)和CV(计算机视觉)模型服务。
- 文本分类: 识别文本的类别(如色情、广告、政治敏感)。
- 情感分析: 判断文本的情感倾向(正面、负面、中性)。
- OCR识别: 识别图片和视频中的文字内容。
- 图像识别: 识别图片中的不良信息(如涉黄、涉暴、违禁品)。
- 风控模型: 结合用户画像、行为序列、设备指纹等信息,构建机器学习模型(如逻辑回归、XGBoost)识别高风险用户和异常行为(如刷单、薅羊毛、欺诈)。
-
任务调度与分发系统:
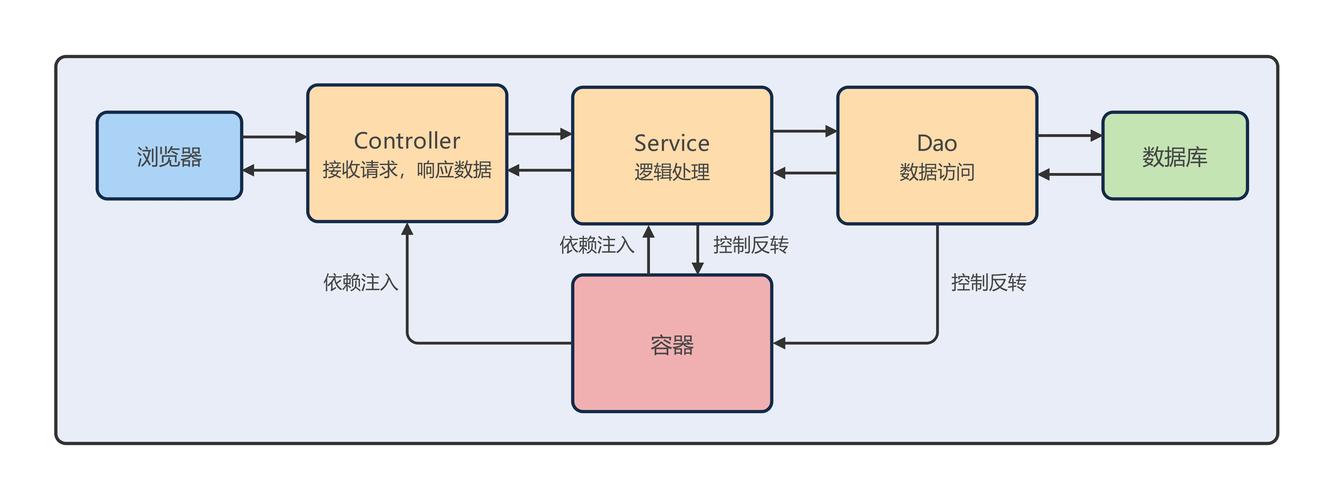 (图片来源网络,侵删)
(图片来源网络,侵删)- 使用 Quartz 或 Elastic-Job 等分布式调度框架,定时触发数据采集、模型训练、数据备份等任务。
- 将待审核的内容(文本、图片、视频)分发给人工审核员或AI模型进行审核。
-
审核工作台:
- 为人工审核员提供Web界面,展示待审核内容、审核规则、历史记录。
- 支持审核员进行“通过”、“驳回”、“标记”等操作,并提供审核建议和辅助信息。
-
处置与执行系统:
- 根据审核结果,自动或手动执行处置动作,如:删除内容、禁言用户、下架商品、封禁账号。
- 提供API接口,将处置指令下发给下游业务系统(如电商平台、社交平台)执行。
监控与可视化层
负责系统的监控、报表分析和数据可视化。
- 实时监控: 使用 Prometheus + Grafana 监控系统健康状态、API性能、数据流量等。
- 数据大屏: 使用 ECharts、DataV等工具,开发可视化大屏,实时展示核心指标,如:今日审核量、违规内容类型分布、风险趋势等。
- 报表分析: 生成日报、周报、月报,分析监管效果,发现潜在问题。
技术架构选型
一个典型的Java互联网监管项目会采用微服务架构,以提高系统的可扩展性、可维护性和容错性。
整体架构:微服务 + 云原生
| 层次 | 技术选型 | 说明 |
|---|---|---|
| 前端 | Vue.js / React | 构建用户交互界面,如审核工作台、数据大屏。 |
| API网关 | Spring Cloud Gateway / Nginx | 统一入口,负责路由转发、身份认证、限流熔断。 |
| 核心业务服务 | Spring Boot / Spring Cloud | 拆分为多个微服务,如:爬虫服务、内容审核服务、风控服务、用户服务、任务调度服务等。 |
| 数据处理 | Apache Flink / Spark Streaming | 实时流处理,用于数据清洗和实时分析。 |
| 搜索引擎 | Elasticsearch | 存储和检索引擎。 |
| 关系型数据库 | MySQL / PostgreSQL | 存储核心业务数据。 |
| 缓存 | Redis | 缓存热点数据(如黑名单、规则配置),提升性能。 |
| 消息队列 | Apache Kafka / RabbitMQ | 服务间解耦,削峰填谷,用于异步处理(如审核结果通知)。 |
| 容器化与编排 | Docker + Kubernetes (K8s) | 实现服务的自动化部署、扩缩容和管理。 |
| 监控告警 | Prometheus + Grafana + Alertmanager | 全链路监控和告警。 |
| CI/CD | Jenkins / GitLab CI | 自动化构建、测试和部署。 |
关键技术与挑战
关键技术点
- 高并发处理: 监控平台需要处理来自全网的海量数据,必须具备高并发、低延迟的处理能力,这需要从架构(异步化、分库分表)、技术(Flink/Spark)和基础设施(K8s弹性伸缩)上综合设计。
- AI模型集成: 将AI能力无缝集成到Java应用中,通常通过 REST API 或 gRPC 调用独立的模型服务,模型服务的性能、准确率和更新频率是关键。
- 数据安全与隐私: 处理大量用户数据,必须严格遵守数据安全法规,数据传输(HTTPS)、存储(加密)、访问(权限控制)都需要严格保障。
- 规则与模型的动态更新: 审核规则和风控模型需要快速响应新的违规手段,系统需要支持规则的动态加载和模型的灰度发布、A/B测试。
主要挑战
- “猫鼠游戏” (Cat-and-Mouse Game): 违规者会不断变换手段规避监管,导致审核规则和模型需要持续迭代,这是一个长期对抗的过程。
- 准确率与召回率的平衡: AI模型不可能100%准确,过于严格(高召回)会导致大量误伤(低准确率),影响用户体验;过于宽松(高准确率)则会漏掉违规内容,需要根据业务场景找到最佳平衡点。
- 海量数据存储与计算成本: 处理PB级的数据,对存储和计算资源的要求极高,成本控制是一个巨大挑战。
- 跨平台、跨协议的数据异构性: 互联网数据来源多样,格式不一(文本、图片、视频、结构化JSON),如何统一处理和分析是技术难点。
未来趋势
- AI深度化: 从“关键词匹配”向“语义理解”和“意图识别”演进,利用大语言模型提升对复杂、隐晦违规内容的识别能力。
- 实时化与预测性: 从“事后处置”向“事中拦截”和“事前预测”发展,通过实时流处理和预测性分析,在违规行为发生前就进行预警和干预。
- 协同治理: 建立跨平台、跨企业的监管联盟,共享黑名单、风险情报和模型能力,形成监管合力。
- 隐私计算: 在不暴露原始用户数据的前提下,进行联合建模和数据分析,以应对日益严格的隐私保护法规。
- 自动化与智能化: 减少人工审核的依赖,通过更强大的AI实现“机器预审 + 人工复核”甚至“全机器审核”的模式,大幅提升效率。
Java互联网监管项目是一个技术复杂度高、业务逻辑严谨、且需要持续迭代的系统工程,它融合了分布式架构、大数据处理、人工智能、网络安全等多个前沿领域的技术,对于开发团队而言,不仅需要扎实的Java技术功底,还需要对数据处理、算法模型和业务场景有深刻的理解,这类项目对于维护网络空间清朗、保障社会稳定和经济发展具有至关重要的作用。


